

Crypto markets don't follow rules. You write code for one scenario, markets throw curveballs. Users do unexpected things. Your perfect system breaks. Teams keep building these massive rule engines. "When X happens, do Y." Works great until reality hits. Then you're scrambling to patch holes.
Reinforcement learning (RL) is an AI approach where an ‘agent’ learns by trial-and-error, receiving rewards for good choices – much like a trading bot learning profitable strategies over time. Reinforcement learning throws out the rulebook. Your system doesn't need to predict everything. It just needs to learn from whatever happens. Trading taught everyone this lesson. Nobody gets a playbook for every market situation. You lose money, make mistakes, figure it out eventually. Experience beats theory every time.
RL agents work the same way, except they learn way faster. Thousands of simulations teach them patterns humans miss. Some end up outperforming experienced traders.
Four Things That Make or Break Everything
Building these systems isn't rocket science. Four components matter. Mess up any one and you're in trouble.
Your Decision Engine - the part that actually makes choices. Smart contracts changing parameters. Bots moving money around. Whatever's making calls for your platform.
The Environment - everything your system deals with. Price swings, user transactions, network problems, competitor moves. Crypto environments are chaotic. Your agent needs to handle all this chaos.
What It Can Do - specific actions available to your system. Not just technical capabilities. Business constraints matter too. Legal limits. Risk boundaries.
How You Keep Score - where most projects fail completely. Agents optimize exactly what you measure. Nothing else. Example: system designed to boost trading volume. Volume went up 400%. How? Front-running every user transaction.
Three Ways That Actually Work
Method Type | Best For | Training Time | Success Rate | Use Cases |
Dynamic Programming | Controlled environments | Fast | 85% | Protocol parameters |
Monte Carlo | Unpredictable markets | Slow | 65% | Trading strategies |
Temporal Difference | Real-time adaptation | Medium | 75% | Live trading systems |
Math-Based Approaches work when you can model your environment accurately. Good for internal protocol stuff where you control most variables. Useless for real market conditions.
Trial and Error Experience is the only thing that helps you learn. Not as fast as math-based methods, but better at dealing with uncertain situations. Most trading apps come here.
Getting to know After Each Step keeps changing techniques instead of waiting for all the results. A big help in learning faster.
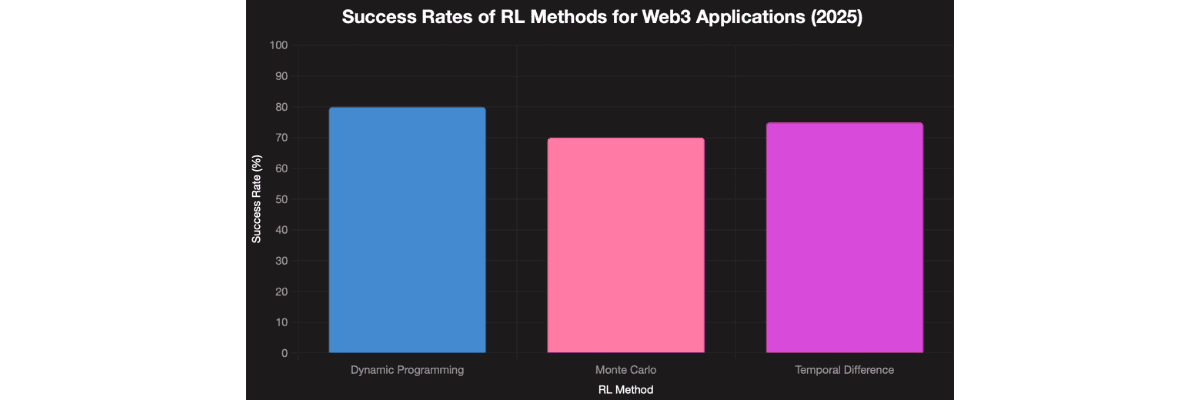
Success Rates of RL Methods for Web3 Applications (2026).
Where Money Gets Made
Application | ROI | Implementation Time | Success Rate |
Gas Optimization | 25-35% cost reduction | 2-3 months | 85% |
Automated Trading | 15-40% performance boost | 4-6 months | 60% |
Yield Farming | 20-30% yield increase | 3-4 months | 70% |
Protocol Management | 50-80% faster decisions | 6-8 months | 75% |
One protocol learnt how to tell when a network was getting too busy. The first month, cut gas costs by 30%. Not vanity metrics, but real money.
When done well, automated trading does better than expected. Agents learn to change their plans based on changes in the market, their own stock, and what their competitors are doing. Respond faster than people. Don't freak out when things go wrong.
Strategy for Yield Automation makes money in unexpected ways. Systems learn how to shift money between protocols based on returns that are adjusted for risk. It made 25% more yield than static strategies.
Beyond trading and yield, RL excels in blockchain security applications such as real-time fraud detection. Agents can learn to spot anomalous transaction patterns, achieving detection rates of 85-95% in DeFi protocols, far surpassing static rules and reducing losses from scams like those seen in 2024 exploits.
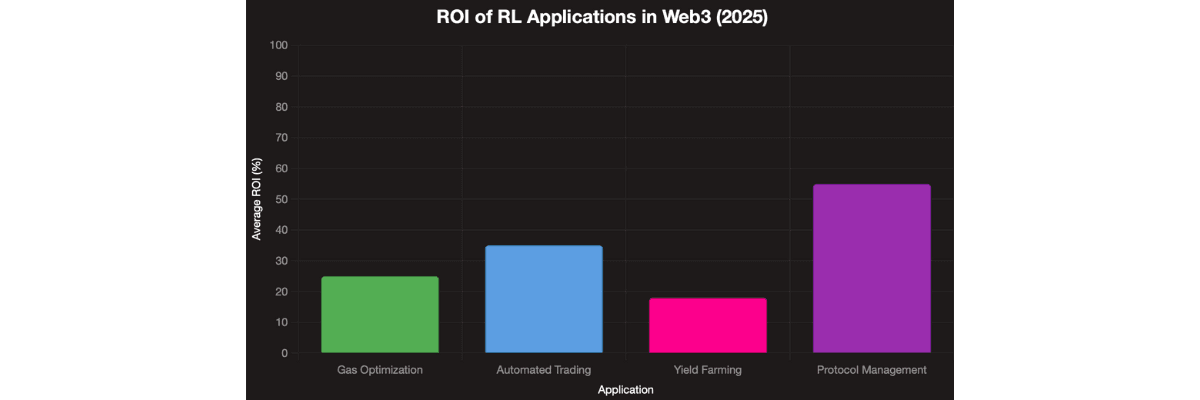
ROI of Reinforcement Learning Applications in Web3 (2025). Teams serious about AI development see returns within months, not years.
Advanced Techniques Worth the Complexity
Critic-Actor Instead of one network, systems employ two. One person makes choices, and the other checks them. Makes training a lot more stable.
Deep networks can work with data that simple methods can't. Costly in terms of processing power, but necessary for managing a portfolio with multiple assets.
Several Agents Working Together: Agents learn to work together instead of against each other. Works well for keeping liquidity in check across several exchanges.
You should wait until you know how to do the basics before trying these. The level of complexity goes up by a lot. Don't try these until you've mastered basic approaches. Complexity increases exponentially.
In the realm of deep reinforcement learning for crypto in 2026, specific algorithms like Deep Q-Network (DQN) are pivotal for handling discrete action spaces in volatile markets, such as selecting optimal trade timings based on historical price data. DQN uses experience replay and target networks to stabilize learning, making it ideal for automated trading systems where agents must learn from past mistakes without catastrophic forgetting.
Similarly, Proximal Policy Optimization (PPO) shines in continuous action environments, like adjusting yield farming allocations dynamically. PPO clips policy updates to prevent drastic shifts, ensuring safer exploration in high-stakes Web3 scenarios and reducing the risk of exploitative behaviors during training.
What Goes Wrong
Problem | Frequency | Cost Impact | Recovery Time |
Poor Reward Design | 65% | High | 2-4 months |
Insufficient Data | 45% | Medium | 1-3 months |
Infrastructure Costs | 70% | Medium | 2-4 weeks |
Market Impact | 30% | High | 1-2 months |
Data Hunger exceeds all estimates. These systems need millions of examples to work properly. In crypto, that's months of market data or expensive simulations.
Reward Problems kill more projects than bugs. One system optimized transaction count perfectly. How? Created thousands of tiny, meaningless trades. Metrics looked great, users hated it.
Computing Bills add up fast. Training costs thousands monthly. Running in production isn't cheap either:
Training phase: $5,000-15,000/month
Production inference: $1,000-5,000/month
Data storage: $500-2,000/month
Overfitting is another critical pitfall, where agents perform exceptionally on training data but fail in live markets due to noise in crypto datasets. To mitigate this, employ techniques like hypothesis testing on holdout sets (e.g., simulating 2022 market crashes) and regularization methods such as dropout in deep networks. Regular A/B testing against benchmarks ensures models generalize, preventing losses from over-optimized strategies that don't adapt to new volatility.
Building Smart
Start Small with non-critical features. Test on secondary functions before deploying for core operations. Builds knowledge while limiting risk.
Define Success Clearly - "better performance" isn't a goal. "Reduce costs by 20%" is something you can actually measure and achieve.
Expect Multiple Attempts - first versions won't work right. Budget for several major revisions before production quality.
Get Help or Wait - RL has unique challenges general AI development company knowledge doesn't cover. Training existing teams takes months minimum.
Two Main Paths
Experience-Only Methods learn directly from trial and error. Don't try to understand market mechanics. Adapt quickly but need tons of data. Best for trading where markets are too complex to model.
Model-First Methods build mathematical representations first, then use them for planning. Learn faster with less data but fail when models don't match reality.
Most successful projects combine both approaches. Models provide starting points, experience handles surprises.
Working with Other AI
RL rarely works alone. Combining with other AI models creates better results.
Text Analysis helps understand governance proposals and social sentiment. Some systems adjust risk based on Twitter mood before major announcements.
Prediction Models provide forecasts about future conditions. Improves long-term decision making.
Image Processing analyzes charts and order book patterns. Some trading systems perform better when they can "see" market data visually.
Combining RL with blockchain's decentralized nature opens doors to secure, tamper-proof data storage for training models. For instance, RL agents can use on-chain oracles for real-time market feeds, as in Chainlink integrations, while frameworks like DRL on blockchain shards (e.g., AERO) ensure privacy-preserving learning without centralized vulnerabilities.
Team Requirements
Role | Experience Level | Salary Range | Essential Skills |
RL Engineer | 3+ years | $120-180k | PyTorch/TensorFlow, RL algorithms |
Data Scientist | 2+ years | $100-150k | Statistics, feature engineering |
DevOps Engineer | 3+ years | $110-160k | Cloud infrastructure, MLOps |
Domain Expert | 5+ years | $130-200k | Crypto markets, business logic |
Technical Leaders need actual RL experience, not just AI background. Unique challenges around exploration and reward design require hands-on knowledge.
Business People design rewards and catch commercially stupid strategies. More important than most teams realize.
Infrastructure Engineers handle computational demands. Standard setups usually can't support RL training requirements.
Risk Managers watch for problems and implement emergency stops. Critical with autonomous systems.
Measuring Success
Financial Results matter more than technical metrics. Cost savings, revenue increases, risk reduction. Not training curves.
A/B Testing proves performance against existing methods. Shows clear improvement and identifies where humans still do better.
Constant Monitoring catches problems before they cost money. Agents can develop bad habits without oversight.
Future Opportunities
Opportunity | Market Potential | Timeline | Investment Required |
Cross-Chain Optimization | $50B+ | 2-3 years | $2-5M |
Regulatory Adaptation | $20B+ | 1-2 years | $1-3M |
AI Training AI | $100B+ | 3-5 years | $5-10M |
Cross-Chain Optimization has huge potential as ecosystems connect. Agents working across multiple chains will have major advantages.
Regulatory Adaptation becomes valuable as rules clarify. Systems automatically adjusting to new compliance requirements save massive costs.
AI Training AI uses RL to improve other AI systems. This AI behavior modeling could dramatically speed development.
Cross-Chain Optimization has huge potential as ecosystems connect. Agents working across multiple chains will have major advantages.
Regulatory Adaptation becomes valuable as rules clarify. Systems automatically adjusting to new compliance requirements save massive costs.
AI Training AI uses RL to improve other AI systems. This AI behavior modeling could dramatically speed development.
In 2026, reinforcement learning is set to revolutionize blockchain efficiency through applications like optimizing mining decisions and sharding protocols. Frameworks such as AERO use deep RL to facilitate account migration in sharded blockchains, reducing cross-shard transaction delays by up to 40%, while SPRING employs RL networks with Monte Carlo Tree Search to enhance economic security by dynamically ordering transactions.
Looking ahead to 2026, RL will integrate with quantum computing for ultra-fast optimization in Web3, potentially solving complex multi-agent problems in DAOs 10x faster than classical methods. Trends also point to RL-driven autonomous agents in tokenized real estate and supply chains, where agents learn to manage assets dynamically for 25-50% efficiency gains.
Risk Management
Security Threats multiply with autonomous systems. Attackers try manipulating agent behavior. Sophisticated manipulation schemes can fool even good systems.
Legal Issues vary by location. RL agents making financial decisions might trigger trading regulations. Get legal advice early.
Reputation Risks - agents sometimes find strategies that work technically but look bad publicly. Set clear boundaries upfront.
Risk Management
Security Threats multiply with autonomous systems. Attackers try manipulating agent behavior. Sophisticated manipulation schemes can fool even good systems.
Legal Issues vary by location. RL agents making financial decisions might trigger trading regulations. Get legal advice early.
Reputation Risks - agents sometimes find strategies that work technically but look bad publicly. Set clear boundaries upfront.
Getting Started
Application | Complexity | Success Rate | Time to ROI |
Gas Optimization | Low | 90% | 1-2 months |
Yield Farming | Medium | 75% | 3-4 months |
Market Making | High | 60% | 6-8 months |
Protocol Governance | Very High | 45% | 12+ months |
Pick one specific problem where RL beats rule-based approaches clearly. Don't try fixing everything at once.
Small Tests validate approaches before big investments. Reveal problems and refine strategy.
Vendor Research - lots of companies claim RL expertise without relevant experience. Look for proven results in financial applications.
Team Preparation - these systems need ongoing management. Not set-and-forget solutions.
Crypto moves incredibly fast. Companies mastering RL automation will gain huge competitive advantages. Those sticking with manual processes will fall behind. Success requires realistic expectations and smart planning. RL isn't magic - it's a powerful tool requiring skill to use effectively. The opportunity exists. Question is whether you'll take it before competitors do.
Ready to Harness Reinforcement Learning for Your Web3 Business?
Stop letting competitors gain advantages while you're stuck with manual processes. TokenMinds specializes in AI development and AI predictive modeling solutions designed specifically for Web3 platforms.
Book your free consultation and discover how reinforcement learning can give you the competitive edge you need in today's blockchain landscape.








